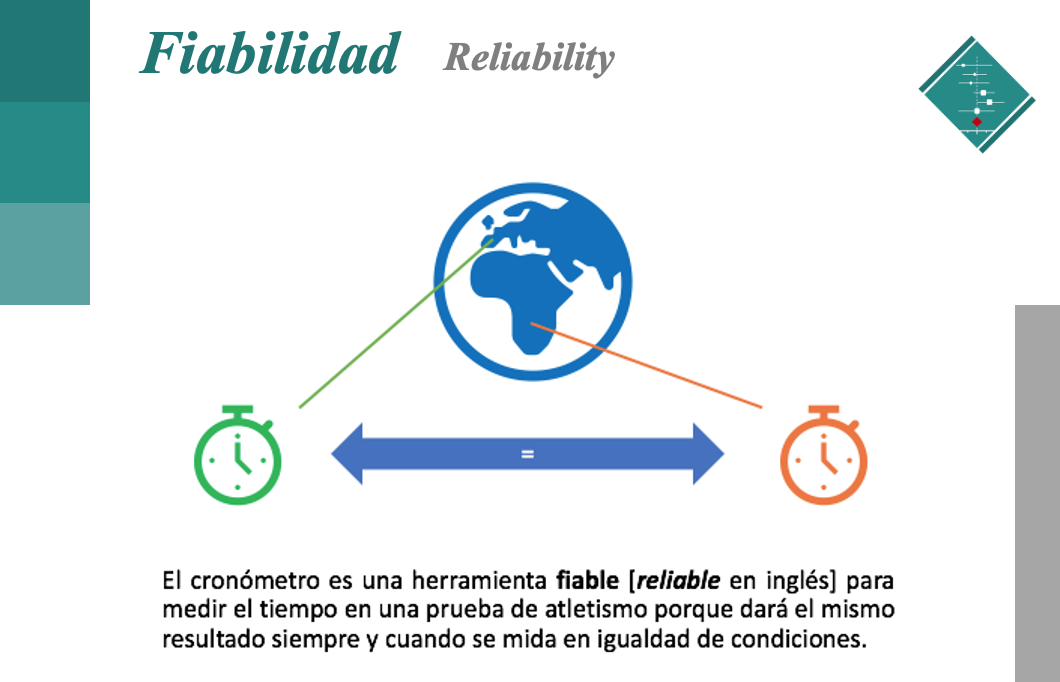
Anteriormente hemos visto que cualquier herramienta de medición debe ser fiable para poder llevar a cabo una determinada investigación. No hay que olvidar que una medida fiable [reliable measurement en inglés] no es sinónimo de una alta calidad de la misma. Para ello, dicha herramienta debe presentar una adecuada validez. Podemos definir validez [validity en inglés] como el grado en el que un instrumento mide realmente lo que debe medir.
Si tomamos por ejemplo un matraz de Erlenmeyer, como el que vemos en la siguiente imagen, este podrá medir adecuadamente los mililitros (ml) del líquido que le metamos. Por lo tanto, el matraz presenta una excelente validez para medir precisamente el volumen de los líquidos equivalentes a la milésima parte de un litro. Seguramente si usásemos un baso de una cocina corriente sin escala de ml en el laboratorio, la medida "no sería válida" (de hecho usaríamos estas palabras literales) y, por lo tanto, diremos que el vaso de beber agua no es un instrumento válido para medir el volumen de un líquido. Como ya se ha indicado en entradas anteriores, el concepto de validez no es tan intuitivo en otro tipo de instrumentos de medida como las encuestas.

Sin embargo, la validez no es una propiedad intrínseca del test, instrumento o herramienta de medida, sino más bien de la propia interpretación de lo que ese instrumento está midiendo (Cook y Beckman, 2006). Los resultados de un instrumento serán válidos cuando las interpretaciones son justificables en el seno (o contexto) de lo que la herramienta va a medir (Kimberlin y Winterstein, 2008). Entonces, las conclusiones que se van a extraer de los resultados del instrumento de medida deben estar basadas en lo que la evidencia teórica del momento pueda sostener en la interpretación final del resultado. De esta forma, no es de extrañar que las interpretaciones divergentes se deban también que tener en cuenta (Messick, 1989).
Validar un instrumento de medida nos es otra mas a que establecer un nexo profundo y estable de los resultados obtenidos (con el instrumento) y el estado del arte de la teoría que sustenta su uso [theory-based assumptions en inglés]. En consecuencia, se debe partir siempre de la premisa que el constructor objeto de análisis nunca será perfectamente reflejado por un test "perfecto" en el que el objetivo es establecer ocrrelancioens entre los ítems tan altas como sean posibles (Cook y Beckman, 2006).
La validez es a su vez un constructo complejo o multifacético. De manera general existen tres enfoques principales para inspeccionar la validez de los instrumentos que se van a usar en las investigaciones: la validez de contenido, la validez de constructo y la validez de criterio.
Validez de contenido - Content validity
La validez de contenido describe el alcance en el que los items de una escalas representan "fielmente" el constructo que el instrumento quiere medir para que, precisamente, las medidas sean relevantes (Almanasreh et al., 2019).
Normalmente para evaluar la validez de contenido se emplean paneles de expertos en la materia que indican qué cuestiones son relevantes para un determinado constructo. Además, una vez elaborado los ítems candidatos que formarán el instrumento de medida, serán evaluados por una puntuación numérica por dicho panel de expertos para así obtener el Índice de Validez de Contenido [Content Validity Index (CVI) en inglés].
La validez de contenido se suele tener en cuenta incluso antes de haber creado el instrumento de medida. Esto hace que de manera externa al grupo de creación del instrumento sea muy complicada su evaluación.
Validez de constructo - Construct validity
Este tipo de validez fue introducido por primera vez por Cronbach y Meehl en 1955. Se define como el grado de concordancia entre los resultados de la medida y la teoría establecida que la sustenta. De este modo, la validez de constructo "obliga" a tener en cuenta que el instrumento mida todas las facetas (conocidas) del concepto objeto de estudio (esto es: el constructo) de una manera adecuada.
Gracias a la validez de constructo, mejoramos la visión de la validez ante cualquier instrumento. Ahora ya no solo tenemos que observar si el instrumento en cuestión mide exactamente lo que debe medir, sino que además debe estar en armonía con la red nomológica con otros constructos teóricamente relacionados.
Para evaluar la validez de constructo se realizan análisis estadísticos de correlaciones con varias medidas. El patrón de correlación resultante ofrece información sobre el grado de conformidad entre la medida global y las variables predictivas teóricas (Westen y Rosenthal, 2003). A su vez, la validez de constructo se compone de dos grandes bloques: la validez convergente y la validez discriminante.
- Validez convergente [Convergent validity en inglés]. Tipo de validez que se da cuando los distintos instrumentos de medida que dicen medir el mismo constructo correlacionan alto con cada uno de ellos. En otras palabras, es la prueba que confirma que los constructos que se esperen que estén relacionados, realmente lo estén.
- Validez discriminante [Discriminant validity en inglés]. Tipo de validez que se se da cuando los distintos instrumentos de medida que dicen medir constructor distintos no correlacionan entre sí. Es decir, se trata de la prueba que confirma que los constructos que no deberían tener ninguna relación, realmente no la presenten.
Validez de criterio - Criterion validity
Por último, la validez de criterio mide la relación entre una variable externa, un índice o un indicador del concepto que se está midiendo con el propio instrumento de medida (Guirao-Goris et al., 2016). Dicho de otro modo, para que un instrumento adquiera una adecuada validez de criterio, debe tener un alto grado de confirmada con criterios prácticos, relevantes y externos.
Dentro de esta validez se asume, por tanto, que el instrumento no puede considerarse como algo aislado, sino más bien como algo que está en relación con otras variables significativas.
Fuentes bibliográficas
- Almanasreh, E., Moles, R., & Chen, T. F. (2019). Evaluation of methods used for estimating content validity. Research in Social and Administration Pharmacy, 15, 214-221. https://doi.org/10.1016/j.sapharm.2018.03.066
- Cook, D. A., & Beckman, T. J. (2006). Current concepts in validity and reliability for psychometric instruments: theory and application. The American Journal of Medicine, 119(2), 7-16. https://doi.org/10.1016/j.amjmed.2005.10.036
- Guirao-Goris, S. J. A., Ferrer Ferrándiz, E., y Montejano Lozoya, R. (2017). Validez de criterio y de constructo del diagnóstico de enfermería" estilo de vida sedentario" en personas mayores de 50 años. Revista Española de Salud Pública, 90, 1-9.
- Kimberlin, C. L., & Winterstein, A. G. (2008). Validity and reliability of measurement instruments used in research. American Journal of Health-System Pharmacy, 65(23), 2276-2284. https://doi.org/10.2146/ajhp070364
- Messick, S. (1989). Validity. In R. L. Linn (Ed.), Educational measurement (pp. 13 -103). America Council on Education & Macmillan
- Western, D., & Rosenthal, R. (2003). Quantifying construct validity: two simple measures. Journal of Personality and Social Psychology, 84, 608-618. https://doi.org/10.1037/0022-3514.84.3.608
Jacob Sierra Díaz