El concepto de fiabilidad [reliability en inglés] es muy importante cuando se emplean instrumentos de medida en investigaciones rigurosas para poder obtener conclusiones precisas. Para explicar este importante término, vamos a tomar como ejemplo el uso de un cronómetro para medir una prueba de velocidad en atletismo.
Imaginemos que esta prueba de velocidad se hace en un país del continente europeo y, a su vez, se está repitiendo en un país del continente africano. Para ello se están usando dos cronómetros del mismo modelo y características. Al finalizar las pruebas, cabría esperar que los dos instrumentos hayan obtenido el mismo resultado, siempre y cuando se hayan dado las mismas condiciones. Dicho de otro modo y observando la siguiente ilustración, si un corredor autómata y gran experto que siempre clava su tiempo en 14 segundos repitiese la misma prueba bajo las misma condiciones de temperatura, humedad, material de la pista, etc en los dos continentes; los cronómetros que se hayan usado deberían medir exactamente 14 segundos. Si por ejemplo, un cronómetro marcase un valor de 30 segundos en lugar de 14 segundos (que es lo que realmente ha tardado el corredor en acabar la prueba) no sería ni un instrumento ni una medida fiable [unreliable en inglés]. El cronómetro defectuoso tiene un gran error de medición [measurement error en inglés]. Entonces, como los cronómetros miden con precisión los segundos y mili segundos independientemente de los modelos a emplear, diremos que el cronómetro es una herramienta fiable para medir esta prueba.
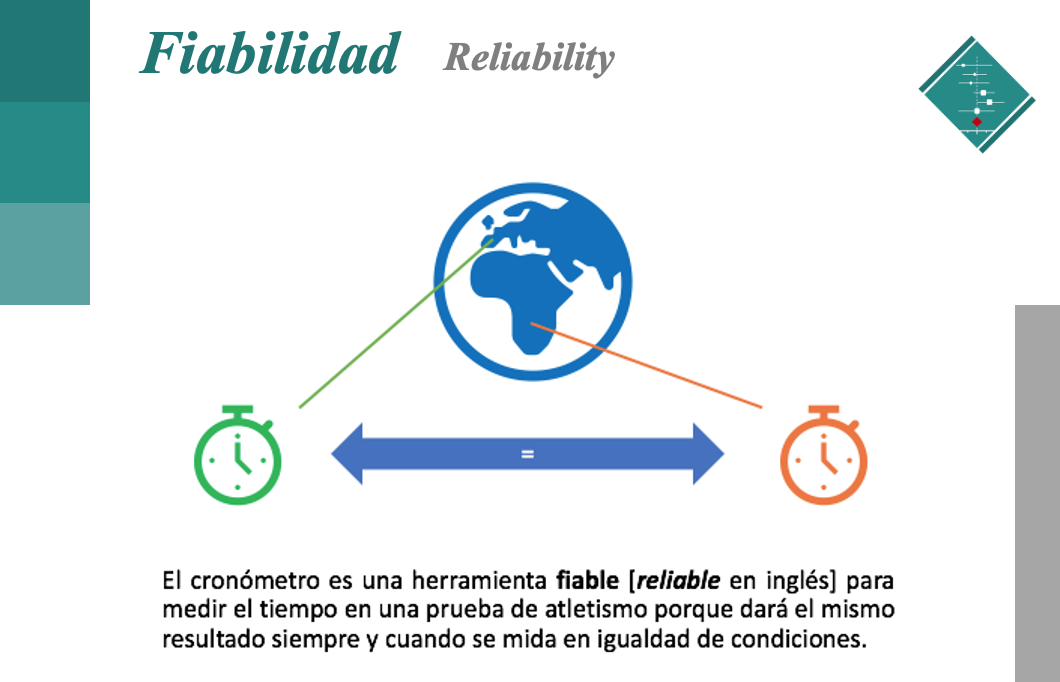
La fiabilidad [reliability en inglés] se puede definir como la consistencia de un instrumento de medida (Schuurman y Hamaker, 2019). Esta breve definición indica que un instrumento o herramienta, como el caso del cronómetro, es fiable cuando tiene un mínimo o nulo error en la medición. Volviendo al ejemplo anterior, tal y como hemos visto, el cronómetro es fiable [reliable en inglés] porque medirá los segundos de manera adecuada y precisa en cualquier prueba llevada a cabo en cualquier parte del mundo.
Entonces, podemos decir que una medida es fiable cuando se obtiene el mismo resultado bajo las mismas condiciones de medición del constructo (Heale y Twycross, 2015). Siguiendo con ejemplo anterior, si usamos dos cronómetros para medir la prueba de un corredor, estos deberán de dar el mismo resultado (siempre y cuando se hayan accionado y parado a la vez).
El concepto de fiabilidad se entiende muy bien en instrumentos o medidas "objetivas" como son los cronómetros o la magnitud de segundo. Sin embargo, en investigación no siempre se usan herramientas en las que asumimos una fiabilidad "tan estable". La fiabilidad se vuelve más compleja con instrumentos como los cuestionarios o las escalas de medida psicológicas (entre otras ramas de estudio). Si bien nadie suele dudar de la fiabilidad de un cronómetro, las escalas humanas de investigación deben ser evaluadas en términos de fiabilidad. Por ejemplo, una escala de motivación puede ser o no fiable para medir el constructo de motivación autodeterminada en una población de estudiantes universitarios.
En la mayoría de investigaciones de carácter social o sanitario (entre otras ramas de conocimiento) se emplean instrumentos ad hoc. Normalmente suelen ser escalas compuestas por varios ítems que abordan algún aspecto importante del constructo objeto de estudio. Para este tipo de instrumentos se hace preciso evaluar el concepto de fiabilidad a través de la Estadística. Los valores estadísticos de las mediciones de nuestros instrumentos nos informan de hasta qué punto lo que estamos usando para medir el constructo está libre de errores de medición y puede ser replicado en otra parte del mundo. En términos generales, existen tres principales procedimientos para poder evaluar la fiabilidad de las mediciones asociadas a las herramientas de toma de datos:
- Procedimiento o test de fiabilidad paralelo [parallel test reliability en inglés]. Para este procedimiento se emplean dos versiones del instrumento objeto de análisis de la fiabilidad que se presentan a los participantes varias veces. Normalmente, las dos versiones del instrumento suelen cambiar la sintaxis de los ítems o incluso el orden de los mismos. Al acabar la recogida de datos con los dos instrumentos se comparan las medidas de ambas escalas y se evaluan las posibles diferencias.
- Procedimiento de fiabilidad test-retest [test-retest reliability en inglés]. A diferencia del procedimiento anterior, usamos una única versión del instrumento que se proporciona a los participantes varias veces en momentos de tiempo distinto. Al acabar la recogida de datos, se comparan las medidas del instrumento en función del momento en el que se haya respondido y se evalúa las posibles diferencias.
- Procedimiento de división por mitades [split-half reliability en inglés]. Para este procedimiento se dividen al azar las mediciones o los elementos del instrumento (por ejemplo los factores de una escala) en dos grandes grupos. A continuación, se analiza la correlación entre los dos grupos. Este procedimiento asume que la herramienta que debe medir el constructo deseado se haga consistentemente en todos los ítems que forma la herramienta (Cho, 2016).
Fuentes bibliográficas
- Cho, E. (2016). Making reliability reliable: a systematic approach to reliability coefficients. Organizational Research Methods, 19, 651-682. https://doi.org/10.1177/1094428116656239
- Heale, R., & Twycross, A. (2015). Validity and reliability in quantitative studies. Evidence-based Nursing, 18, 66-67. https://doi.org/10.1136/eb-2015-102129
- Schuurman, N. K., & Hamaker, E. L. (2019). Measurement error and person-specific reliability in multilevel autoregressive modeling. Psychological Methods, 24, 70-91. https://doi.org/10.1037/met0000188

Jacob Sierra Díaz
No hay comentarios:
Publicar un comentario